Running your LLM for inference with Ollama¶
1. Log into Discovery Environment¶
Log into https://de.cyverse.org.
If you have not yet created an account, go to the User Portal to sign up.
2. Launch the JupyterLab Pytorch GPU App¶
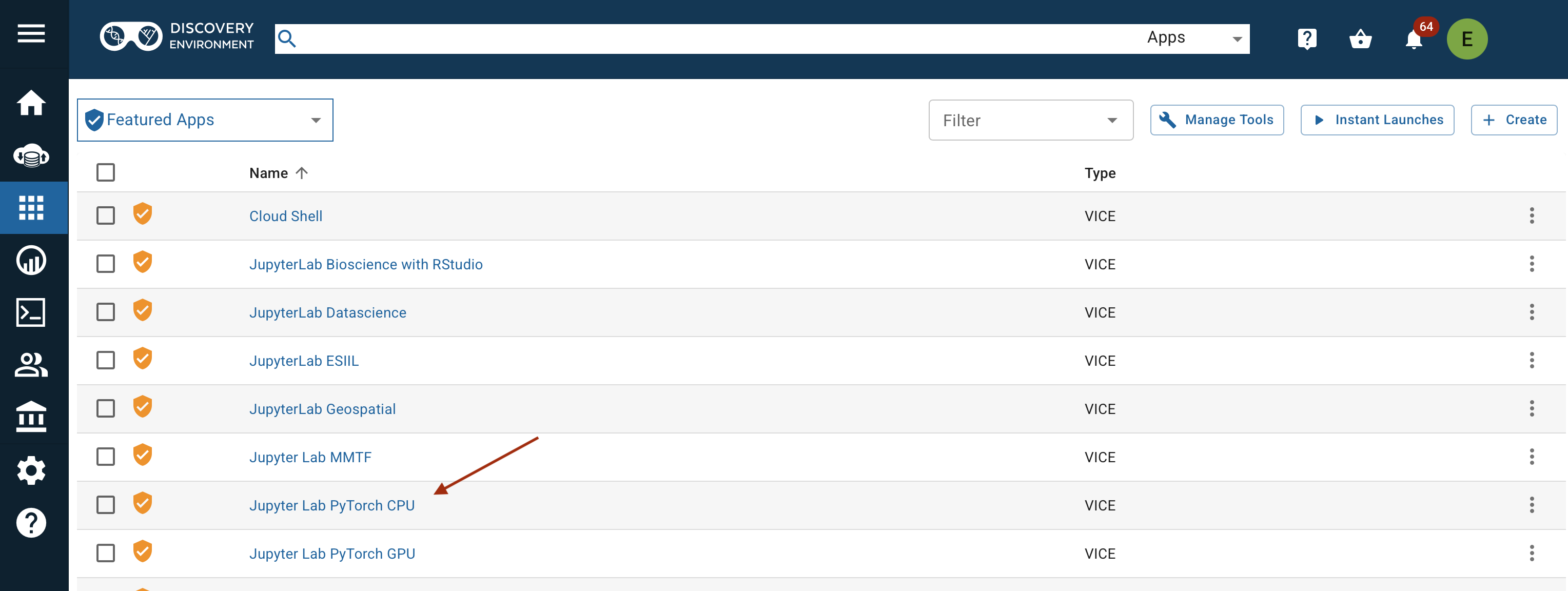
Click on the Apps grid icon.
Jupyter Lab Pytorch GPU is in "Featured Apps".
Instant Launches start Apps immediately when clicked.
The conventional launch menu allows you to modify the App parameters. You can add input data, increase the amount of RAM or CPU cores, and change the analysis directory.
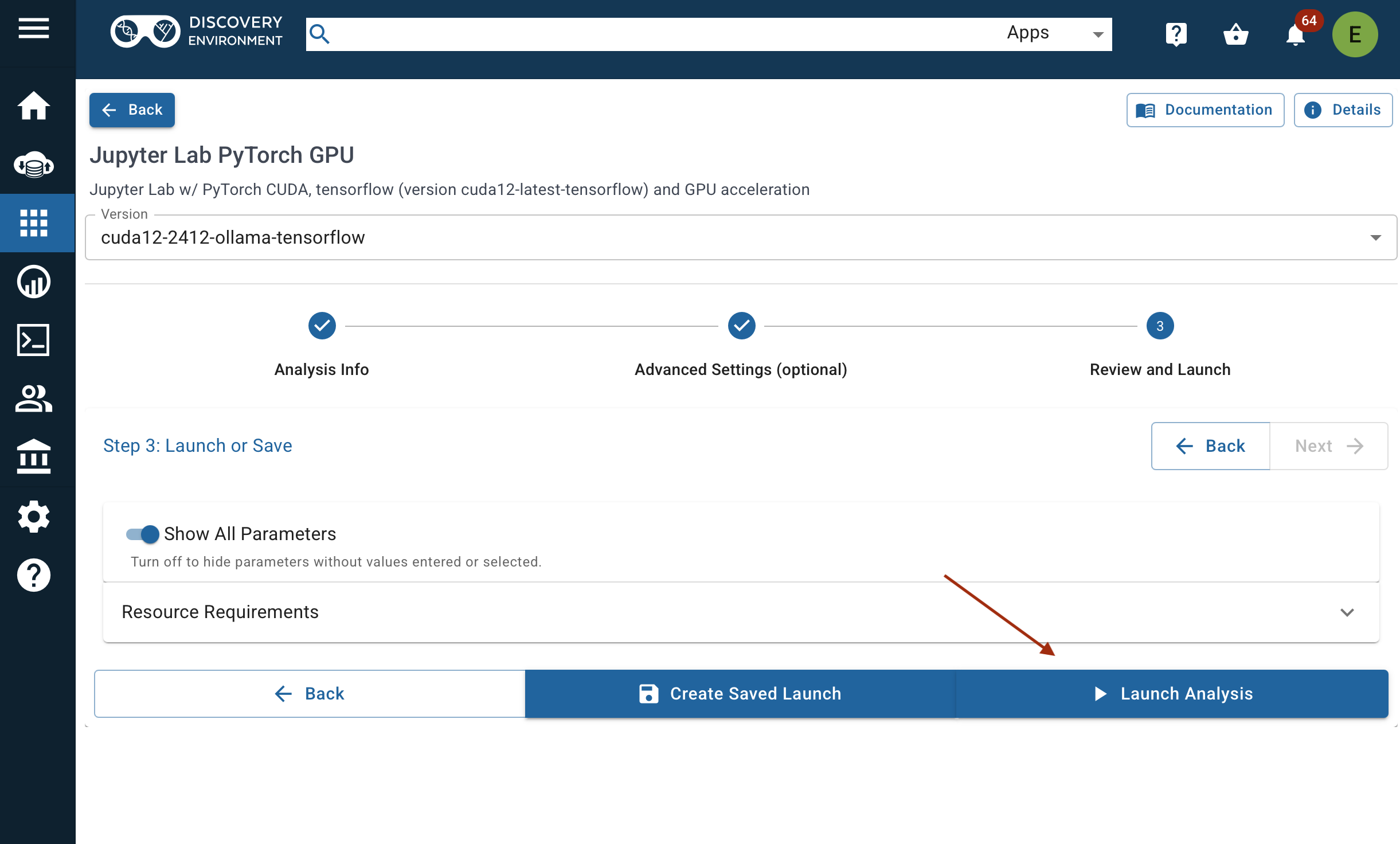
3. Open the Analysis¶
After you have started a VICE app, a new tab will automatically open in your browser and take you to the loading screen.
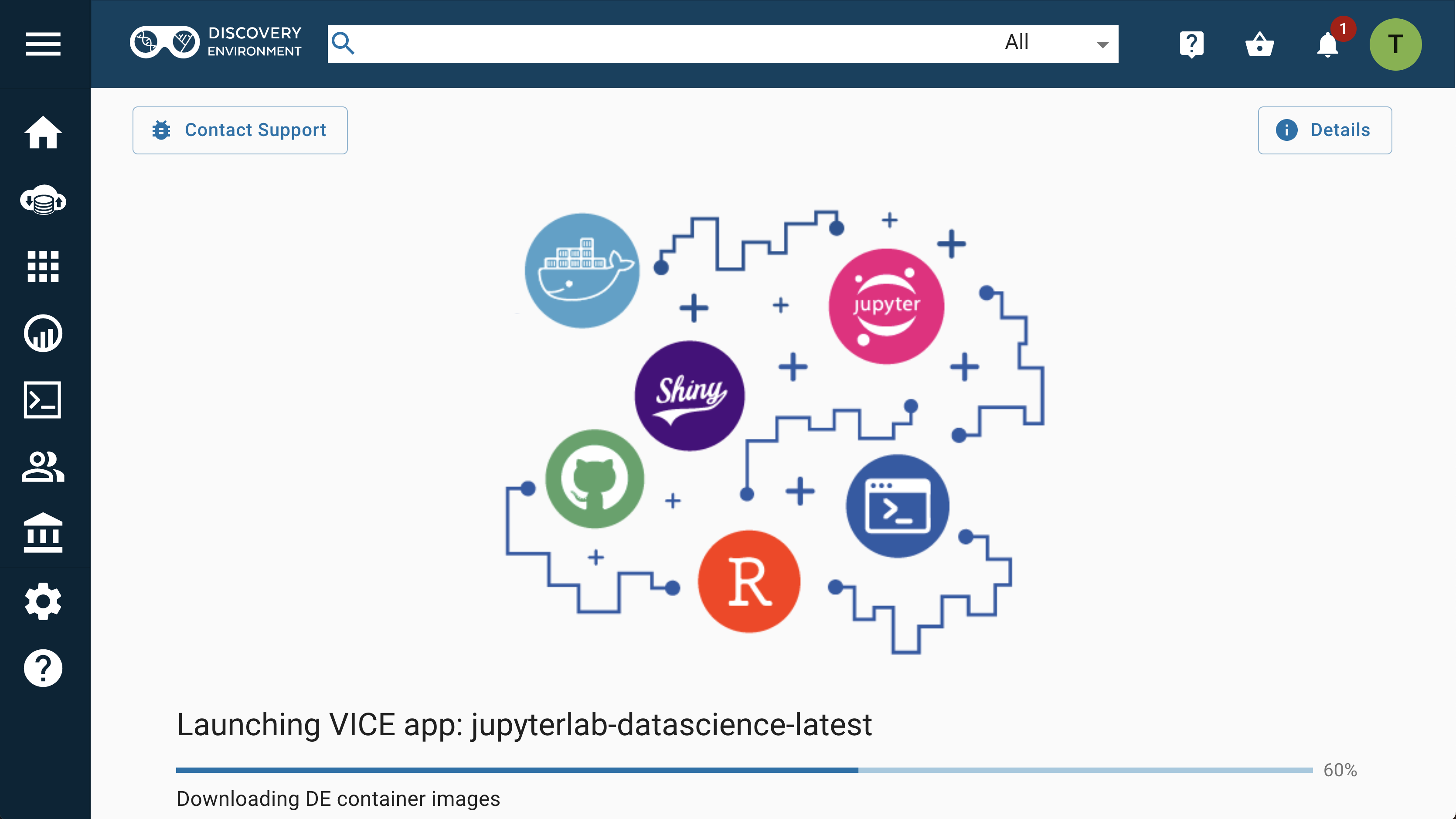
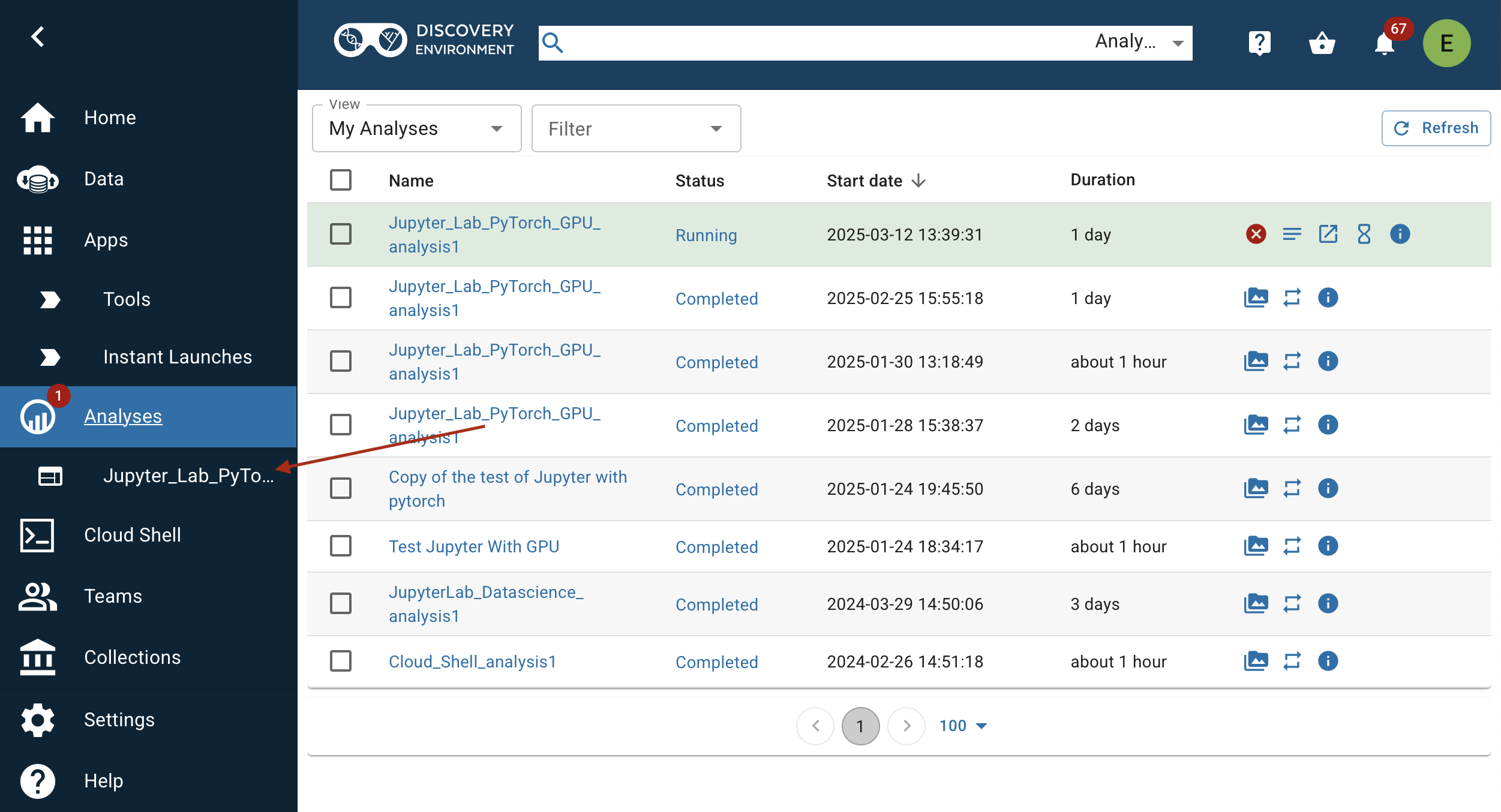
Once the app is ready, it will transition to the user interface.
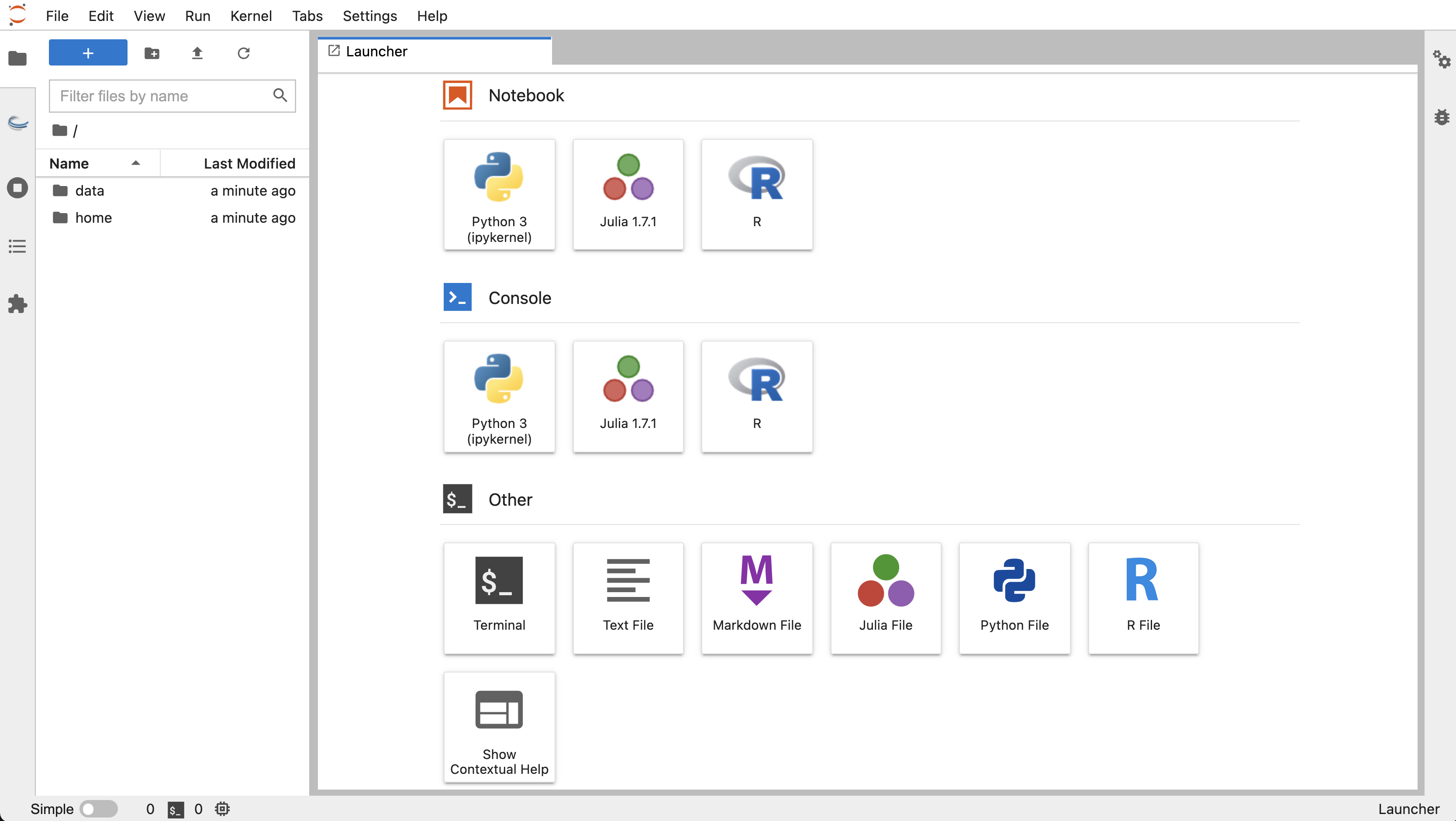
We will focus on running an llm for inference using Ollama as a server. The Jupyter Lab with Pytorch GPU, comes with Ollama preinstalled, which is necessary to run LLMs. The Jupyter Lab interface consists of a main work area containing tabs of documents and activities, a collapsible left sidebar, and a menu bar. The left sidebar contains a file browser, the list of running kernels and terminals, the command palette, the notebook cell tools inspector, and the tabs list.
Long wait times?
Normal wait time for a featured VICE app to launch is less than 2 minutes. If you're experiencing a significantly longer wait, consider terminating the Analysis and starting a new one.
4. Download and run an LLM using Ollama¶
From Jupyter's Launch menu, select the black Terminal console icon.
This will take you to a command line shell.
Run the following command to start Ollama in server mode:
$ ollama serve
Open a new tab with a console and then, pull the model you're interested in. For example llama 3.1:
$ ollama pull llama3.1
5. Create Jupyter notebook to interface with the LLM.¶
After starting Ollama in server mode and downloading the relevant models, you can run your code that uses the aformentioned models.
To create a notebook, click the + button which opens the new Launcher tab.
To open the classic Notebook view from JupyterLab, select "Launch Classic Notebook" from the Help Menu.
Create a new jupyter notebook to where can use any llm client library to interface with the LLM. DataLab has a reference notebook with a usage example using ollama's client libary.
Alternatively, you can use langchain, llama-index, the OpenAI API client library or any other client library that speaks OpenAI's REST API.
6. Terminate your app¶
The Discovery Environment is a shared system. In fairness to the community, users should "Terminate" any apps that are no longer actively running analyses.
In the Analyses window, select the app (by clicking the checkbox next to it), select "More Actions", then "Terminate" to shut down the app.
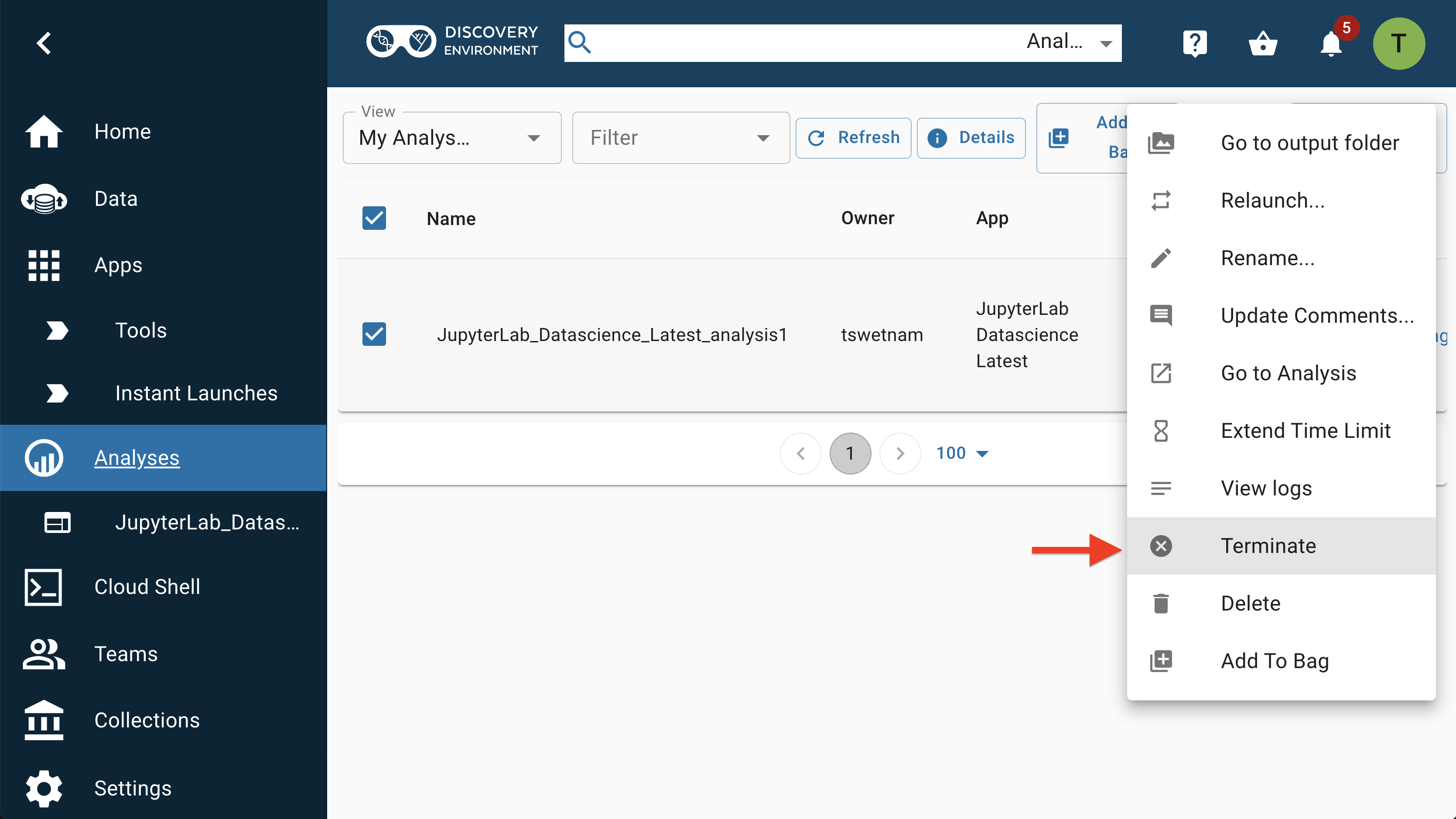
Any new data in the /home/jovyan/work/data/outputs directory will begin copying back to your folder at this time.
Any input data which you added when the app started using the conventional launch feature will not be copied.
Automatic Termination and Extension
VICE apps run for a pre-determined amount of time, typically between 4 and 48 hours. If you have opted for email notifications from the DE, then you'll get a notification 1 day before and another 1 hour before the app will terminate.
To extend the pre-set run time, go to your analysis and click the hour glass icon which automatically extends the app run time.